knowledge
management
Ján Paralič
(editor)
Publisher:
Technical University
Kosice
ISBN:
978-80-553-2100-4
Table of Contents
1.1 Knowledge and Knowledge management – main
concepts
1.2 Knowledge management systems
1.5 Factors influencing knowledge management
1.6 Knowledge management impact and evaluation
2.1 Domain
Knowledge Modelling in KnowWeb
2.4.1 Pilot
Application for Retail
2.4.2 KnowWeb
as a Knowledge Management extension of existing Electronic Document
Management System
2.5.1 System
Functional Overview
Ontology-based
Information Retrieval
TRIALOGICAL LEARNING
IN PRACTICE
Example for
exercises – information retrieval part
1
Introduction
This textbook
provides additional study material for the Knowledge
management subject, which is taught at the Faculty of Electrical
Engineering
and Informatics, Technical University in Kosice in engineering study
programs
of Business information systems and Intelligent
systems.
This subject
is divided into the following major parts:
1.
Knowledge
and Knowledge management – main concepts
2.
Knowledge
management systems
3.
Information
retrieval
4.
Text mining
5.
Factors
influencing knowledge management
6.
Knowledge
management impact and evaluation
Each of these
major parts is briefly sketched in the following
subsections and references to relevant work especially at our
department, are
provided in the following subsections.
1.1
Knowledge
and Knowledge management – main concepts
Within the
first part of the subject, core concepts relevant to
knowledge management are explained and discussed in details. In
particular
these concepts and themes are discussed:
·
Individual
levels of work with knowledge (i.e. supranational, national,
organizational and
the level of knowledge management).
·
The role
and place of knowledge in organizations (why knowledge is so important
to
organizations)
·
Data,
information, knowledge [11]
o
What it is,
what are the connections and differences between them
o
Definitions
of knowledge
o
Types of
knowledge:
§
The ability
to express knowledge is the most important aspect of knowledge types,
i.e.
there is explicit and tacit knowledge
§
Psychology
of knowledge: declarative and procedural
§
Owner of
the knowledge: individual and collective
·
What is and
what is not knowledge management
o
Definitions
of knowledge management and their common features
o
Intellectual
capital and its structure
o
Value of
knowledge for an organization
·
Knowledge
management framework
o
Knowledge
management framework types
o
Knowledge
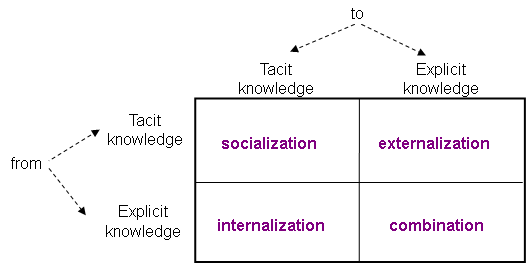
life cycle by Nonaka and Takeuchi [12] – see also Figure 1.
·
Different
points of view on knowledge management, in particular:
o
Conceptual
view: definitions of knowledge and knowledge management, knowledge
principles,
knowledge management frameworks
o
Process
view: identification and understanding of different types of knowledge
processes
o
Technological
view: how different information, communication and knowledge
technologies
assist in the implementation of knowledge management
o
Organizational
view: focuses on solving problems of knowledge organization
characteristics and
its proper formal and informal organizational structures, tasks,
responsibilities
and organizational learning
o
Implementation
view: identification of practices and procedures that enable successful
implementation of knowledge management, see e.g. [16]
o
Management
view: Different procedures that lead to knowledge management
implementation
into practice, e.g. management procedures, measurement and evaluation
of
intellectual capital, reward, salary and motivational systems,
development of
appropriate corporate culture
Figure
1 Knowledge lifecycle
model by Nonaka and Takeuchi
1.2
Knowledge
management systems
Within the
second part of the knowledge management subject we focus on
knowledge management systems [17], starting
with presentation and explanation of a general knowledge management
system architecture [3], which
consists of four main parts:
1.
The flow of
knowledge
·
Supports
interaction between tacit knowledge that is exchanged and generated in
communities of knowledge workers (4) with the explicit knowledge that
is stored
in the knowledge sources (2) and meta-knowledge by which the
organization maps
its presence
2.
Knowledge
repositories and libraries
·
Provides
effective organization, intelligent access and reuse of accumulated
explicit
knowledge stored in various documents (whether in paper or in
electronic form).
3.
Knowledge
cartography
·
The mapping
of all types of knowledge in organization and its efficient search and
retrieval (i.e. main focus of the organization, individual knowledge,
customer
database, etc.).
4.
Communities
of knowledge workers
·
Interplay
between teams and communities, informal working methods and formal
processes in
organizations.
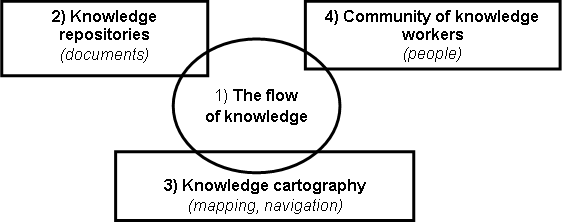
Figure 2 Knowledge management
systems – general
architecture [3]
We further
discuss learning processes in organizations [3]. At the
global level learning processes can be
divided into:
1.
Top–down
learning, i.e. strategic learning (management at particular level of
management
recognize a promising area and take the decision to acquire knowledge
in this
area)
2.
Bottom–up
learning, which includes processes in which the individual worker
learns
something that can be useful for the organization (lesson learned).
This
experience is distributed further in the organization.
Lesson
learned is any positive or negative experience that can improve
organizational performance in the future. For knowledge management it
is of
particular interest the bottom-up learning, which is reflected in three
basic
forms of learning, taking place in parallel in the organization:
1.
Individual
learning
2.
Learning
through communication (group learning)
3.
Learning by
development of a knowledge repository.
In the next
part of this theme we present particular examples of knowledge
management
systems following the general architecture of knowledge management
systems (see
above).
We first
start with knowledge repositories (sometimes called also organizational
memories [1]), where
explicit knowledge is stored. There are 4 main types of knowledge
repositories (see Table 1 below),
depending on two essential features of a knowledge repository,
namely the
way knowledge is inserted to the repository (either passively or
actively) and
the way how knowledge is retrieved from the repository (passively or
actively).
Table
1 Typology
of knowledge repositories
|
Lessons learned (pieces of knowledge) |
Passive collection |
Active collection |
|
Passive distribution |
Knowledge attic |
Knowledge sponge |
|
Active distribution |
Knowledge publisher |
Knowledge pump |
The knowledge attic type of knowledge
repository is used as an archive, if necessary. The advantage is that
it is not
"intrusive system". It emphasizes the bottom-up nature of
organizational
learning. It requires high discipline of the workers in the company.
Example of
KR of this type is SELL[1] (Space
Engineering Lessons Learned).
The knowledge sponge type of knowledge
repository signifies that the organization is actively trying to
develop more
or less complete knowledge repository, because it actively collects
lessons
learned into the knowledge repository. Whether the knowledge repository
is
actually used to improve the quality of the organizational processes is
left to
individual workers. A possible example of this type of system is KnowWeb [7], [15], which has
been designed and developed by the team from our university in European
research projects KnowWeb in years
1998-2000. For
more details about particular aspects of this system see chapter 2. Especially
some
of the user requirements which arose from the application described in 2.4.1 was the main
driver to design a “knowledge sponge” type of knowledge repository, not
only
knowledge attic, as originally planned.
The knowledge publisher type of knowledge
repository is typical by the fact that asserting lessons learned is
left to the
individual workers. The role of administrators of the knowledge
repository is
to analyze incoming lessons learned, combine these with knowledge in
the
knowledge repository and forward them to the workers for whom the
lesson
learned might be relevant. Example of KR of this type is DOELLIS[2] (Department
of Energy Lessons Learned Information Services).
The knowledge pump is the most complex type
of knowledge repository. In theory, this model ensures that the
knowledge
developed in the organization is fully exploited to improve its
performance.
The management of the organization enforces an efficient functioning of
the
lessons learned cycle. Example of KR of this type is CALL[3] (Center of
Army). Another examples of the knowledge
pump type of
knowledge repository is the Webocrat
system [13], which has
been designed and developed by the team from our university in European
research projects Webocracy in years
2001-2003. For
more details about particular aspects of this system see section 2.5.
We further
discuss indexing mechanisms used in knowledge repositories which
ideally should
support three basic types of searching:
1.
Hierarchical
searching – the knowledge items are organized in a fixed hierarchical
structure
(e.g. tree structure in Webocrat ).
2.
Attribute
searching – by specifying values for attributes. The search mechanism
returns
the knowledge items that have the specified values on the attributes.
3.
Content
searching – entering arbitrary search terms related to the topic of
interest.
The search mechanism returns all knowledge items in which the term
occurs,
possibly with a relevance score.
Example of
knowledge management systems supporting communities of knowledge
workers are
CSCW (Computer Supported Cooperative Work) systems, providing numerous
applications (groupware) to support various specific aspects of
cooperative
work, e.g.:
·
Workflow
management
·
Share
documents
·
Video-conferencing
An example
implementation of such a system is PoliTeam
a system,
integrating all above mentioned three forms for mediated cooperation,
used by
the German Ministry for Science, Technology and Education [3]. Another
excellent example is the KPE (Knowledge Practices Environment)
platform, which
has been designed and implemented by a large international consortium
of 6th
frameworks program EU integrated project KP-Lab[4], where team
from our university played an important role. For more detailed
description of
KPE and accompanying tools see chapter KNOWLEDGE
PRACTICES LABORATORY,
in particular section KP-LAB
APPLICATIONS.
1.3
Information
retrieval
Text document
is one of the most common forms of explicit knowledge
representation. This is the reason, why one part of the knowledge
management
subject is devoted to information retrieval [2], [5]. Information
retrieval is focused on storing
information and later access to this stored information. In this
subject we
first explain the information retrieval process both and continue with
basic
and alternative models for information retrieval.
Two main
information retrieval modes, namely Boolean and vector models
are described in greater details. Probabilistic model and selected
alternative
models are described only on the level of their main principles. For
each of
the three main models, their advantages and disadvantages are explained.
One of the
possible forms of inner document representation usable for
Boolean model is term-document incidence matrix. Showing the problem of
fast
growing size of incidence matrix, inverted index is presented and
explained,
together with the algorithm for its construction and efficient search
(processing of basic queries by means of inverted index). Especially
algorithm
for conjunctive queries evaluation is presented and explained, as well
as basic
principles of more complex queries optimization.
As next,
consideration of term occurrence frequency in document as well
as in the whole document collection is presented, coming to the vector
model
idea, including various types of weighting schemes.
Finally,
evaluation of information retrieval systems [5] is presented
and explained. There are different
criteria used for evaluating of information retrieval systems, e.g.
·
Evaluation
of retrieval efficiency (user satisfaction)
·
Precision,
recall, F-measure as measures for evaluation of results without
ordering
(unranked retrieval set)
·
Graphical
representation of the precision-recall curve – for ranked retrieval set
·
Summary
measures of IR efficiency
We also
discuss methods how to further improve quality of information
retrieval systems. One way of doing this is to use semantic information
in form
ontologies [4] for
annotation of documents to concepts from a
knowledge model [17]. These can
then be exploited for indexing and
searching. In this area of research we achieved very interesting
results that
we presented in [19], which
currently has 76 citations on Google
Scholar. This publication is included here as chapter entitled Ontology-based
Information Retrieval.
One lecture
is devoted to the specific aspects of information retrieval
on the web. We start with a very brief history of web search and
continue with
explanation of the crawler-indexer architecture [5], basic
requirements for the crawler and its basic
architecture. We discuss three basic types of user queries, categories
and economical
aspects of web search, search based marketing and the way how AdWords
works. In
web search, structure of the links is used to adjust the search
results. In
this respect two main algorithms are explained:
·
PageRank
algorithm
·
HITS
algorithm
1.4
Text
mining
Information
retrieval is a first necessary step in efficient
organization of explicit form of knowledge. Nevertheless its
interpretation is
left on intelligent reader. Text mining [8]provides
means to go one step further. Text mining
namely aims at discovery of hidden patterns in textual data [14]. For this
topic, there is available a textbook [9], which we
wrote in Slovak for our students. It
describes the whole process of knowledge discovery from textual
collections. We
describe in details all preprocessing steps (such as tokenization,
segmentation, lemmatization, morphologic analysis, stop-words
elimination), we discuss various models for
representation of text
documents and focus on three main text mining tasks:
1.
Text
categorization [10], [26]
2.
Clustering
of textual documents [23], [24]
3.
Information
extraction from texts [25], [27]
Finally, we
describe service-oriented view on text mining and present
also selected distributed algorithms for text mining. Second part of
the
textbook [9] is devoted
to description of our JBowl (Java Bag of
words library) [20], presenting
its architecture, selected
applications and a couple of practical examples, which help our
students easier
start for practical work with JBowl on
their own text
mining problems. Some basic information about the architecture,
functionality
and selected applications are described also here, in final chapter of
this
book, entitled Design and evaluation of
a web system
supporting various text mining tasks for purposes of education and
research,
which was published in [22].
1.5
Factors
influencing knowledge management
Universalistic
view of knowledge management assumes that there is a
single best approach to knowledge management in any organization [18]. This would
mean that it would be sufficient to
apply this one, the best approach to knowledge management. Although it
rarely
occurs in the literature explicitly, but often such an argument
implicitly
exists, e.g. knowledge sharing is universally recommended as an
appropriate
solution to support knowledge management. However, there are situations
(small
firms) where this approach is too expensive and a better solution is
appropriate direction.
Contingency
view on the other hand assumes that none of the existing
approaches to knowledge management is the best in all situations. This
approach
assumes that there are several alternative paths to success of
knowledge management,
which depend on a number of specific circumstances of the
organization. In
this part of the subject we list and explain the main influencing
factors,
which need to be taken into account when deciding about suitable
knowledge
management strategy. These factors influence what knowledge processes
are
important in particular organization. The following categorization of
knowledge
processes by [18] is used in
this part of our knowledge management
subject:
1.
Knowledge
discovery:
·
Combination
(suitable for explicit knowledge)
·
Socialization
(suitable for tacit knowledge)
2.
Knowledge
capture:
·
Internalization
(of explicit knowledge)
·
Externalization
(of tacit knowledge)
3.
Knowledge
sharing:
·
Distribution,
or exchange (suitable for explicit knowledge)
·
Socialization
(suitable for tacit knowledge)
4.
Knowledge
application:
·
Routines
(for explicit and tacit knowledge)
·
Direction
(for explicit and tacit knowledge)
The following
are the most influencing factors for knowledge management
decisions [18]:
1.
Task
characteristics in the department (organization)
·
Task
uncertainty
·
Task
interdependence
(on results of other departments)
2.
Knowledge
characteristics for solving tasks
·
Explicit
vs. Tacit
·
Procedural
vs. Declarative
3.
Organizational
characteristics
·
Size of the
organization
·
Business
strategy
4.
Environmental
characteristics
·
Extent of
uncertainty
After
detailed analysis what particular influencing factors mean and
what types of knowledge processes they influence, we present a
methodology for
deployment of systems supporting knowledge management in organisations as
defined in [18]:
1.
Assess the
contingency factors
2.
Identify
appropriate knowledge processes for each contingency factor
3.
Prioritize
the needed knowledge processes
4.
Identify
the existing knowledge processes
5.
Identify
the missing knowledge processes (based on comparison of 3. a 4.)
6.
Asses the knowledge
management infrastructure
7.
Develop
additional needed knowledge
management systems, mechanisms and organizational measures
Finally, we
present an example, demonstrating how presented methodology can be
applied in a
particular company.
1.6
Knowledge
management impact and evaluation
Final part of
the knowledge management subject is devoted to identification of four
levels,
where knowledge management has best potential to influence positively
organizations [18]:
1.
Impact
of knowledge management on people in organization: employee learning,
their
adaptability and job satisfaction
2.
Impact
of knowledge management on processes in organization: effectiveness,
efficiency, innovation
3.
Impact
of knowledge management on products of the organization: value added
products,
knowledge based products
4.
Impact
of knowledge management on overall performance of the organization
(direct and
indirect impacts)
Finally, we
discuss various aspects of knowledge management evaluation [18], in
particular the following ones:
1.
When to
evaluate the knowledge management (both knowledge management solutions
as well
as impact of knowledge management on organization):
·
At the
beginning of a knowledge management project
·
At the end
of the knowledge management project
·
Periodically
further on
2.
How to
evaluate the knowledge management
·
Qualitatively,
e.g. interviews with employees, observation, and examples of working
(not
working) actions
·
Quantitatively,
i.e. using precise numerical metrics (gained by the processing of
questionnaires or by evaluation of the economic indicators as return on
investments, or cost savings)
3.
What, i.e.
which aspects of knowledge management should be evaluated
·
People
·
Processes
·
Products
·
Overall
performance of the organization
References
[1]
Abecker
A., Bernardi A. Hinkelmann
K. Kühn, O. & Sintek
M. (1998):
Toward a Technology for Organizational Memories, IEEE Intelligent
Systems,
13, May/June, p. 40-48.
[2]
Baeza-Yates,
R.
& Ribeiro-Neto, B. (1999) Modern
Information
Retrieval. Addison-Wesley Longman Publishing Company.
[3]
Borghoff
U. M.
& Pareschi R. Eds. (1998) Information
Technology
for Knowledge Management. Springer Verlag.
[4]
Chandrasekaran
B.,
Josephson J.R. & Benjamins V.R. (1999)
What Are
Ontologies and Why Do We Need Them. IEEE Intelligent Systems, 14, p.
20-26.
[5]
Manning,
C.D., Raghavan,
P., Schutze,
H.: Introduction to Information Retrieval, Cambridge University Press,
2008
[6]
Gruber T.R.
(1993) A Translation approach to Portable
Ontology
Specifications. Knowledge Acquisition, 5, 2.
[7]
Paralic,
M., Sabol, T. & Mach, M. (2000) System
Architecture for
Support of Knowledge Management. Int. Journal of Advanced Computational
Intelligence, Vol. 4, No. 4, Fuji Technology Press Ltd., Japan
[9]
J. Paralič,
K. Furdík, G. Tutoky,
P. Bednár, M. Sarnovský,
P. Butka, F. Babič:
Text Mining (in Slovak: Dolovanie
znalostí z textov).
Equilibria, s.r.o.,
Košice, 2010, 184 p.
[10]
Sebastiani,
F.:
Machine learning in automated text categorization. Journal ACM
Computing
Surveys (CSUR). Vol. 34, Issue 1, March 2002, p. 1-47
[11]
Newell A.
(1982) The
Knowledge Level. Artificial
Intelligence, 18, p. 87-127.
[12]
Nonaka
I. &
Takeuchi H. (1995) The Knowledge Creating Company: How Japanese
Companies
Create the Dynamics of Innovation. Oxford
Univ. Press.
[13]
Paralič,
J. & Sabol, T. (2001) Implementation
of e-Government Using
Knowledge-Based System. Proc. of the 12th Int. Workshop on Database and
Expert
Systems Applications, (Workshop on Electronic Government), Munich,
364-368.
[14]
Paralic,
J.,
Bednar, P.: Text mining for document annotation and ontology support.
Intelligent Systems at the Service of Mankind, Ubooks,
2003, p. 237-248
[15]
Dzbor,
M., Paralic, J., Paralic,
M.: Knowledge management in a distributed organisation. Advances in networked enterprises,
Kluwer
Academic Publishers, London, September 2000, pp. 339-348
[16]
Tiwana
A. (2000) The Knowledge Management Toolkit,
Practical Techniques for
Building a Knowledge Management System. Prentice Hall, 2000
[17]
van
Heijst G., Schreiber A.T. & Wielinga,
B.J. (1997) Using explicit ontologies in KBS development. Int. Journal
of
Human-Computer Studies, 46, p. 183-292.
[18]
Becerra-Fernandez,
I. - Gonzalez, A. - Sabherwal,
R.:
Knowledge Management - Challenges, Solutions, and Technologies.
Pearson,
Prentice Hall, 2004
[19]
J. Paralic,
I. Kostial: Ontology-based
information retrieval. Proceedings of the 14th International Conference
on
Information and Intelligent systems (IIS 2003), Varazdin,
Croatia, p. 23-28
[20]
Bednar, P.,
Butka,
P. and Paralic,
J.: Java library for support of text mining and retrieval. In Proc.
from Znalosti 2005, Stara
Lesna, High Tatras,
2005, p.
162-169
[21]
F. Babič, P. Bednár,
K. Furdik, J. Paralič,
M. Paralič, J. Wagner: Trialogical
learning in practice. Acta Electrotechnica
et Informatica Vol. 8, No. 1 (2008), p.
32–38
[22]
Furdík,
K., Paralič, J., Babič,
F., Butka, P., Bednár,
P.: Design and evaluation of a web system
supporting various
text mining tasks for the purposes of education and research. In: Acta Electrotechnica
et Informatica.
Vol. 10, No. 1
(2010), s. 51-58
[23]
Sarnovský,
M., Butka, P., Paralič,
J.: Grid-based support for different text
mining tasks. In: Acta Polytechnica Hungarica.
Vol. 6, no. 4 (2009), p. 5-27
[24]
Rauber,
A., Pampalk, E., Paralič,
J.:
Empirical Evaluation of Clustering Algorithms. Journal of Information
and Organizational
Sciences 24 (2), 195-209
[25]
Sarawagi
S.
Information extraction: Foundations and Trends in Databases, vol. 1
(2007), no.
3, pp. 261-377
[26]
Machová,
K., Bednár, P., Mach, M.: Various
approaches to web information
processing. In: Computing and Informatics. Vol. 26, No. 3 (2007), p.
301-327
[27]
Machová,
K., Maták, V., Bednár,
P.: Information extraction from the web pages using machine learning
methods.
In: Information and Intelligent Systems. - Varaždin
:
Faculty of Organization and Informatics Varaždin,
2005, p. 407-414
2
Knowledge
modelling
Authors: Ján Paralič,
Marián Mach, Tomáš,
Sabol
Knowledge can be simply defined as actionable information [7].
That means that (only) relevant information
available in the right place, at the right time, in the right context,
and in
the right way can be considered as knowledge. The knowledge life cycle
defined
in [[10]]
hinges on the distinction between tacit and explicit
knowledge. Explicit knowledge is
a formal one and can be found in documents of an organization: reports,
manuals, correspondence (internal and external), patents, pictures,
tables
(e.g. Excel sheets), images, video and sound recordings, software etc. Tacit knowledge is personal knowledge
given by individual experience (and hidden in peoples’ minds).
A considerable amount of explicit knowledge is
scattered throughout various documents within organizations. In many
cases this
knowledge is stored somewhere within the organization, but without
possibility
to be efficiently accessed (retrieved) and reused any more. As a result
of
this, most knowledge is not sufficiently exploited, shared and
subsequently
forgotten in relatively short time after it has been introduced to,
invented/discovered within the organization. Therefore, in the
approaching
information society, it is vitally important for knowledge-based
organizations
to make the best use of information gathered from various information
resources
inside the company and from external sources like the Internet. On the
other
hand, tacit knowledge of authors of the documents’ provides important
context
to them, which cannot be effectively intercepted.
Knowledge management [7]
generally deals with several activities relevant in
knowledge life cycle [1]:
identification, acquisition, development,
dissemination (sharing), use and preservation of organization’s
knowledge. From
these activities, dissemination (sharing) is crucial. Knowledge that
does not
flow, is not disseminated and shared (within an organization or a
community),
does not grow and eventually becomes (sooner than ‘normal’) obsolete
and
useless. By contrast, knowledge that flows, by being shared, acquired,
and
exchanged, generates new knowledge [3].
Our approach to knowledge management supports most of
the activities mentioned above. Based on this approach, KnowWeb[5] toolkit [7]
has been designed, implemented and tested on five
pilot applications. Firstly, it provides tools for capturing and
updating of
tacit knowledge connected with particular explicit knowledge inside
documents.
This is possible due to ontology model, which is used for
representation of organization’s
domain knowledge. Ontology with syntax and
semantic rules provides the 'language' by which KnowWeb(-like)
systems can interact at the knowledge
level [5].
Theoretical
foundations for the research of
domain modelling can be found in the works of [3],[6],[13],
and others on ontologies and knowledge modelling. Ontology is a
term borrowed from philosophy where it
stands for a systematic theory of entities what exist. In context of
knowledge
modelling, Gruber
[6]
introduced the term ontology as a set of definitions
of content-specific knowledge representation primitives consisting of
domain-dependent classes, relations, functions, and object constants. The ontology
represents formal concepts using which the
knowledge can be represented and individual problems within a
particular domain
can be described. Ontology in this sense determines what can 'exist' in
a
knowledge base. Chandrasekaran [4]
understands ontology as a representation vocabulary
typically specialized to some domain. He suggests basically two
purposes why
ontologies may be used.
·
To
define most commonly used terms in a specific domain, thus building a
skeleton.
·
To
enable knowledge sharing and re-using both spatially and temporally -
see also [8].
Ontological
knowledge modelling represents a
technological background on which handling of all documents
(hereinafter the
term “document” corresponds to any piece of information which can be
stored as
a computer file regardless of its content, structure or format
used)
within the KnowWeb system is built.
2.1
Domain Knowledge
Modelling in KnowWeb
It is very difficult to compare documents in order to
find a document that is similar to some other document or relevant to
some
query [2],
especially when the similarity is regarded as similarity
of contents. It means that two documents are similar only in case they
are
about the same or similar topics. And it does not matter whether these
documents have different formal layout or not, or whether they use the
same set
of words.
In order to support document retrieval, different
arrangements of documents can be used. Within these schemas it is
possible to
distinguish two levels. There is a repository of physical
documents
(reports, tables, etc.) on one side. On the other side, background
information
is attached to each document. It can define document’s context, its
relation to
other documents, meta-information related to the document, and its
relation to
organization’s activities.
One possible solution is to use a domain model. This
model describes entities from some (well defined) domain and
relationships
among these entities. Such a ”vocabulary”
with its own
internal structure is known as ontology [4].
Ontology is typically a domain specific – it can
determine what ‘exists’ in a domain. It allows a group of
people to
agree on the meaning of basic terms, from which many different
individual
instantiations, assertions and queries can be constructed.
This model
can play a role of a context for documents.
In order to express the context of the documents explicitly, it is
necessary to
create links between a document and relevant parts of the domain model.
If all
documents are linked to the same domain model, then it is possible to
calculate
the similarity between documents using the structure of this domain
model.
Figure 1
presents an example of a graphical
representation of an ontological domain model. It consists of many
elements. The elements are of two types: concepts and relations between
concepts. Concepts are more or less abstract constructs on which
a relevant part of the world is built, or better, which can be
used to
describe this relevant part of the world. For example, "manager"
is a concept and "manager is an employee" is a relation
between concepts "manager" and "employee".
The result is a network-like structure.
It enables to deduce relationships (its type and/or degree) between
concepts,
e.g. between "manager" and "researcher".
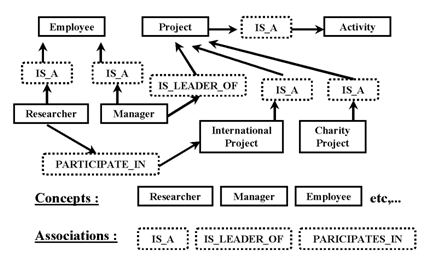
Fig. 1. An example of ontological domain model
The main
purpose of using ontology is to define
concepts and relations that are useful to represent knowledge about a
particular document in domain specific terms. These elements can be
used to
create contextual information attached to documents. Subsequently, the
model
elements can be also used for search and retrieval of relevant
documents. In
such case, the domain model serves as a ‘reference vocabulary’ of
company-specific terms. Such approach supports searching not only in
the
physical document space but also in the document context. It also
supports
‘soft’ techniques where a search engine can utilize the domain model to
find
out related concepts to those specified by the user.
Based on the
needs analysis of several pilot
applications, two types of concepts have been identified as necessary
and
satisfactory as well. They can be either
generic (type class) or specific
(type instance). Both of them have attributes.
Concepts and
relations among them are used to construct a domain model. Formally,
relation in KnowWeb is an oriented link
between two concepts. Two basic types of relations can be
distinguished: subclass_of
for
relations between classes, and instance_of
for relations between classes and their
instances. These two relation types enable inheritance of attributes
and their
values. The inheritance is an important mechanism for development of a
hierarchical ontology. Also multiple inheritance
is
supported, i.e. a class concept can inherit its attributes from several
parent
class concepts. Figure
2 represents an example - a very small
part of a domain knowledge model in OntoEdit
– a KnowWeb tool for creation and management of ontologies.
What shall be
included in the domain model? The
simple but vague answer is - everything what is relevant and important
to
describe a particular domain. In case of a company, such model may
conceptually
describe the company specific concepts, such as its activities,
projects,
customers, employees, market situation, technological trends etc., as
well as
relations among these concepts.
Each
organization has some knowledge already
gathered in the form of various databases and/or documents containing
information about various technologies, products, customers, suppliers,
projects or employees. Each company has usually some internal
procedures how to
perform specific tasks. Simply said – knowledge exists in an
established
environment. This knowledge is traditionally called organization’s goals and know‑how. From the knowledge
modelling perspective a
repository of know-how, goals etc. may be addressed as an organisational
memory or a corporate
memory.
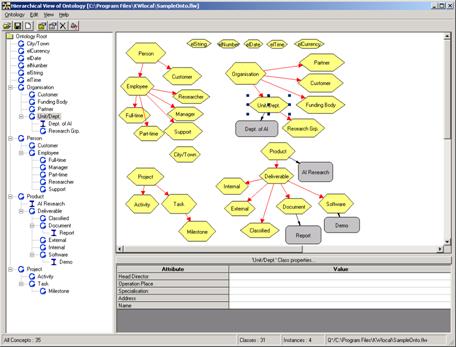
Fig. 2. Sample of a domain knowledge
model (ontology)
2.2
Conceptualisation
The KnowWeb
system enables to an author of a document to store his/her
background knowledge together with the document attaching the relevant
concepts
from ontology –
i.e. document is stored with its context.
In this way
the document description represents a context of the
document and can be used to calculate a “degree of match” between this
document
and a query. The document description enables to express theme of the
document
(what the document is about) in a nutshell. At the same time, it solves
several
language problems, such as ambiguity of a word meaning (multiple
meanings of a
word, i.e. the polysemy problem), synonyms, language morphology, and
language
dependence [2].
The process
of creating a document description is called
conceptualisation. Its aim is to enrich a document with a part of a
domain
model. During this procedure those parts from the domain model are
selected, which
are relevant in some way to the document - e.g. they define the content
of the
document. The outcome of this process is a set of associations between
the
document and the domain model.
Context can
be attached to the document as a whole or to a specific
part(s) of a document called text fragment(s). Text fragment is
a
continual part of text within the document (e.g. a sentence or
paragraph). In
present version, the KnowWeb toolkit is able to process MS Word
documents where
no restrictions are given on text fragments and HTML documents where
text
fragment cannot cross any HTML tag. In order to cope with these
documents the
system provides a set of tools. They differ in their functionality but
together
they enable to document’ authors and users to manage knowledge in a
company in
an easy and user-friendly way.
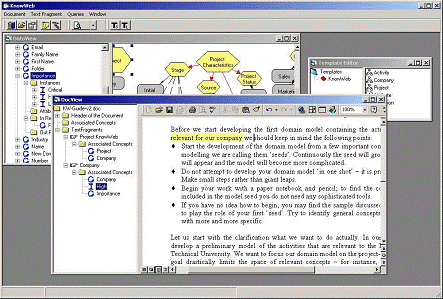
Fig. 3. KnowWeb client interface to
organizational memory
Firstly, in
order to place a document in the organisational memory, it
is necessary to attach context knowledge (i.e. a piece of tacit
knowledge) to
it. This context can be in the form of a conceptual description (CD).
By
conceptual description is meant a set of links between a document (or its marked text fragments) and concepts in the
domain
knowledge model. Conceptual descriptions will enable to refer not only
to
explicit knowledge contained in the document, but also to make use of
tacit
knowledge. In such a way sharing of knowledge in the future is enabled.
The CD
links can be created manually or semi-automatically User can select a
text
fragment and link this fragment to the domain knowledge model. The
linking can
be done directly to ontology concepts or to some template (for
semi-automatic
linking). Association links are of many-to-many type. It means that it
is legal
to link a document (or a text fragment) to several concepts and
obviously, a
concept can be linked to several documents (and or text fragments).
When a
document with its description is available (after manual or
semi-automatic linking within the KnowWeb system or after receiving the
document with its description from outside and consecutive automatic
linking),
it can be incorporated into the organisational memory represented by a
KnowWeb
server. The description of this document is stored in the KnowWeb
server as
well. Another possibility is to store a conceptual description of a
document
without storing the document (the document can be located on other
KnowWeb
server in a distributed company or somewhere else, e.g. on the
Internet). If the author is not satisfied
with the conceptual description of a document stored in the
organisational
memory, he/she has the possibility to modify it and subsequently upload
the
document with the modified description into the organisational memory.
2.2.1. Implementation
The Conceptualisation
tool (CT tool) is built on the
top of three modules, namely DocView,
OntoView, and TemplateEditor (see
Figure 3). The CT tool serves as an “envelope” or
integrator for these modules.
The CT tool is able to deal with two
types of documents. First of all, it is possible to open a new
document, which
will be linked to the corresponding concepts in the domain knowledge
model, and
a copy of this document will be stored on the local KnowWeb server. Two
kinds
of association links are available for this kind of documents.
The purpose
of the DocView
module is to provide users with possibility to preview documents
with option of highlighting those text fragments, which are linked to
the
domain knowledge model. It also supports definitions and modifications
to the
annotation structure of the document, which results in the modified
definitions
of text fragments. Assignment of specific attributes to these text
fragments is
also possible.
The analysis
of pilot applications by our
industrial partners (e.g. application in the retail sector) identified
special
requirement for “automatic” conceptualisation of documents with rigid
structure
(e.g. a structure of daily reports in a retail chain generated each day
in each
shop is fixed). This requirement is fulfilled by so-called “quiet mode”
of the CT tool. In this case no visual
component is started and the documents are linked automatically to
predefined
concepts.
TemplateEditor
module is a good supporting tool for both “quiet” as
well as manual modes of CT tool. The
purpose of this module is to give the users a tool for definition of
special
rules for selection of appropriate concepts. Linking a document (or its
text
fragment) to a template means that association links from this document
(or
text fragment) to all concepts resulted after application of particular
template to present ontology will be created automatically.
In general,
all documents have (possibly empty)
headers, which represent various properties of the documents. For example, they can contain information
regarding the document name, date and time of its creation, authors of
documents, comments, etc. The set of attributes applicable for a header
definition is application-dependent. Some properties may be compulsory
while
others are optional. Within a template three basic kinds of concept
references
are available.
·
A
concept can be directly referenced (only
target concept must be given).
·
A
concept can be a result of an “if – then” rule application to
values of
document properties.
·
A
concept can be referenced
by a document
property. In this case, the name of a concept is determined by the
value of
a document property.
The first two
kinds of references are especially
useful for manual linking, but can be used for automatic linking as
well. The
last type is well suited for the purposes of the quiet mode of the CT tool, i.e. for automatic linking of
whole documents. In this particular case, the target concepts are given
indirectly and depend on the document property values as given in the
document
header.
Moreover,
means for automatic creation of
instances in the domain knowledge model (in the quiet mode) are
provided as
well. This was another user-defined requirement.
2.3
Retrieval
The
aim of storing document in the organisational memory is to access the
right
knowledge at the right time or situation. In order to express
requirements on
documents, which should be retrieved from the organisational memory,
the user
has to formulate a query. To formulate a query he/she can use concepts
(or
their attributes) from the domain model. They can be composed into a
more
complex structure using various operators (e.g. logical connections).
In
general, the concepts specified in the query will be used to search
conceptual
descriptions of documents.
Two basic
models of the retrieval can be distinguished. The ‘exact’
retrieval tries to find documents conceptual descriptions of which
match the
query exactly. In other words, the neighbourhood size of the query
concepts in
ontology is set to zero and only concepts given in the query will be
taken into
account. On the contrary, the ‘approximate’ retrieval returns every
document
connected to domain model concepts, which are ‘close enough’ (size of
the
neighbourhood can be defined) to the concepts mentioned in user’s query.
2.4
KnowWeb
Applications
Botnia Retail Data
Inc. (BRD)
from Finland (http://www.brd.fi/), has
developed two
of the five existing pilot applications based on the KnowWeb system.
Main
business activity of the BRD group is software development and
consultancy for
retail and industry. Their main product is WINPOS®A Point-of-Sale
(POS) software
package.
BRD felt that
the best way to understand how to
use the KnowWeb system is first to use the software within their
organization
with a domain knowledge model suitable for them. The second phase was
the
simulation of a retail environment with a domain knowledge model
suitable for
retail chains.
The database
used was an SQL Server database
running under Windows NT in which documents are stored when they are
finalised.
Each user, who belongs to the personnel of BRD, uses Windows NT
workstations on
which KnowWeb clients are operating. The
documents entered by a user shall typically be linked to a group of
contexts.
In order to quickly find the right contexts where to link the documents
they
have created a number of individual concept conditions. They are
handling
mainly MS Word and HTML documents. They often scan in news articles and
other
printed material, which is first pasted into a MS Word document and
attached
with explanations before the document is stored in the KnowWeb space.
The
advantages identified in BRD after a couple
of months of active KnowWeb using are the following.
1.
Internal efficiency improved. They have been able to organise themselves much
better than before. Now anyone in BRD can access relevant documents
anytime
without having to hunt for a document and wasting time of his/her
colleagues.
2.
Faster customer response. Support personnel are now able to on-line check all
information related to various WINPOS® versions and
features.
3.
Exact and broader feedback to development. They are
tracing competitor information as well as feedback and feature requests
from
their end-users and dealers of their WINPOS® software product.
Before they did not
systematically trace this information. With the new system development
engineers are receiving much better information as a base for decisions
on implementing
updates/upgrades of the given product.
4.
Improved marketing. Due to
systematic entering of competitors’ information and their own marketing
material as well, combined with better feedback information what
features
customers are actually asking for, they have the feeling the system has
helped
them to improve their marketing activities.
On the other
hand the following disadvantages
have been reported:
1.
User
interface of
the KnowWeb system prototype version seems to be too complicated for an
ordinary user.
2.
There is a time overhead in
inserting the documents into the KnowWeb system. During a busy day
this is
simply not being done.
3.
The success of the
introduction of the KnowWeb system to a quite large extent depends
on the
discipline of the staff using it (which means that success
is
dependent also on managerial support).
2.4.1
Pilot
Application for Retail
Most recent retail
chains are using dedicated information systems, so called Point-of-Sale
(POS)
systems, which are planned to generate special information that are
needed in
store- and retail chain environments. Such information is for example
stock-control, campaign control, personnel planning, sales information
per
article group, gross profit information.
These systems are good - as long as things are working as
expected.
Information generated
automatically by present POS applications is and will always be the key
information for the majority of the activities within a retail chain.
Therefore
it is most important to have an access to this information from a
corporate
memory system like the KnowWeb system.
The most interesting
possibilities for a corporate memory system is
in
order to structure all the events that within a retail chain cause
disturbance
to the present information system. These exceptions are in advanced
network
environments most often reported in the form of emails and documents
sent
between retail head office departments and the shops; today often
without
structure, and even forgotten after some time - thus leaving incorrect
information in various databases as reports of present POS information
systems. When planning a campaign or
when making estimates, e.g. regarding profitability on certain article
groups,
the marketing departments are often relying on historical information,
which
may go several years back. If the
figures are unreliable, the decisions taken may be incorrect - the
problem
today is that many of the systems on the market today are not able to
trace
disturbances that have happened in the past.
An example: The new marketing department employee has been
instructed to analyse the effect of a campaign on ice cream that took
place in
week 25, 1998 by comparing the campaign sales with normal weekly sales
of
ice-cream during the summer period. The
existing POS system has generated so called weekly article group report
for the
whole chain - reports that can be easily retrieved from the present POS
system
and compared with reports from other summer-weeks. Comparisons can as
well be
done with reports from similar campaigns the previous year. At a first
glance
she has the information she is looking for - but is the information
reliable? It turns out not, because what
actually happened was that a couple of exceptional things happened that
need to
be considered:
Several large shops
had reported that marketing material for advertisement in local
newspapers had
arrived too late - so the campaign was in some regions delayed by 3
days. A previous
employee had been friendly enough to point out in a report that the
figures of
a similar campaign in 1997 were extreme, because of one of the
coldest
summer weeks this decade. The previous employee had even been friendly
enough
to attach a hyperlink to a meteorological WEB site in the report.
The EDP department
responsible for polling all the shops for sales information had
reported a
major data communication failure the last day of week 25; the sales
information
of the last day of week 25 had been only polled out only on Monday week
26 and
accumulated with week 26 sales information.
In the example above
there were 3 exceptional things that severely affect the reliability of
the
campaign analyses. Without a corporate memory and domain model like the
one in
KnowWeb system, the exceptions would be very hard for the new employee
to find
out with the result that the report to the management would be faulty,
resulting in a high risk of faulty strategic decisions.
Having this in mind,
BRD has linked its WINPOS®
Point-of-Sales software to the KnowWeb system within the second
pilot application. The end-of-day routines in the WINPOS® Point-of-Sales
package
(normally run at the end of the day when the shop has closed) are in
this pilot
application automatically generating shop-specific HTML documents,
which are
automatically introduced to the KnowWeb space. This means that the
html-reports
are automatically inserted into the Know-Web database and automatically
linked
to some predefined concepts via templates (see Figure 4).
Moreover,
certain date-related information leads
to dynamic generation of new instances in the domain model. As examples
of
documents being stored automatically, for example shop-report can be
mentioned,
that is: sales, profit and payment media information summarised for a
shop.
Another example is so-called department report, which contains sales
amount,
quantities and profit for the main article groups of the company. The
advantages the customer will have from this system are:
1
Internal efficiency improved.
2
Faster customer response.
3
Improved marketing.
4
Sales and profit analysing related to disturbances. Automatically created and linked POS reports on one
side are combined within the KnowWeb system with information about
events
causing various disturbances in retail chain (see above) providing
realistic
view on calculated numbers in context of occurred events.
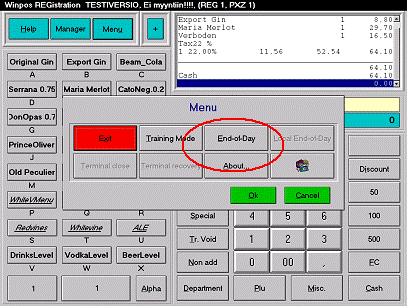
Fig.
4.
WINPOS® Point-of-Sales software. Clicking on the
End-of-Day button will automatically generate the end-of-day report,
translate
it also into HTML format, link using templates onto concepts from
ontology and
upload to the KnowWeb server.
2.4.2
KnowWeb as a
Knowledge Management extension of
existing Electronic Document
Management System
IFBL Slovakia
Ltd. uses a Windows-based software package, CONTACT 2000
(C2K, http://www.contact2000.co.uk/), as the
basic Electronic Data Management System (EDMS).
In the IFBL
Slovakia, Ltd, pilot application, CONTACT
2000 software serves as a general document management
system, and is integrated into the KnowWeb system. Two
related, but separate applications were developed: one for monitoring
and
administration of business transactions, and another one focused on
categorisation of information in the field of electronic commerce.
These
applications show, how the KnowWeb toolkit may be connected with
existing
company’s software for document management and how easy is to use
(submission
and automatic annotation of a new document just by clicking of a button
– see
Figure 5) and exploit functionality of the KnowWeb system (intelligent
retrieval of documents).
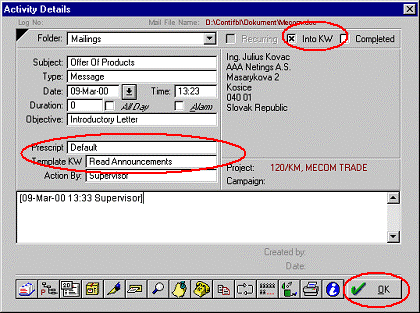
Fig.
5. Inserting
a new activity in Contact2000 EDMS. In order to use the KnowWeb
functionality the
user In addition to the standard
behaviour, user just checks the “Into KW”
option. The attached document will then be uploaded into KnowWeb server. In order to link
the document automatically, user needs to choose a Template and/or
Prescript.
2.5
Webocrat
System
Another, very
interesting application domain is
electronic democracy [[11]].
Architecture of a Web-based system Webocrat[6] has been
designed with the
aim to empower citizens with innovative communication; access and
polling
system supporting increased participation of citizens in democratic
processes
and increase transparency and accessibility of public administration.
The core
knowledge modelling functionality here is analogous to the one of
KnowWeb
system described above. But there are also new interesting and useful
functions
added as described in the following.
2.5.1
System
Functional Overview
From the
point of view of functionality of the system, it is possible to
break down the system into several parts and/or modules. They can be
represented in a layered sandwich-like structure, which is
depicted in
Figure 6.
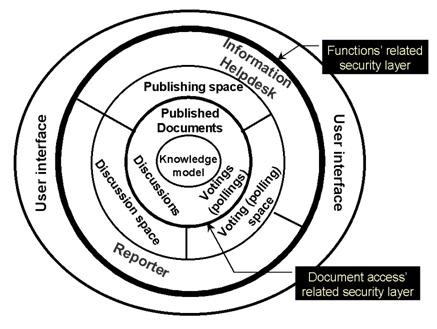
Fig. 6. Webocrat system structure from the point of the
system’s functionality
Knowledge
Model module occupies
the central part of this structure. This system component contains one
or more
ontological domain models providing a conceptual model of
a domain. The
purpose of this component is to index all information stored in the
system in
order to describe the context of this information (in terms of domain
specific
concepts). The central position symbolizes that the knowledge model is
the core
(heart) of the system – all parts of the system use this module in
order to
deal with information stored in the system (both for organizing this
information and accessing it).
Information
stored within the system has the form of documents of
different types. Since three main document types are expected to be
processed
by the system, a document space can be divided into three
subspaces –
publishing space, discussion space, and opinion polling space. These
areas
contain published documents expected to be read by users, users’
contributions
to discussions on different topics of interest, and records of users’
opinions
about different issues, respectively.
Documents
stored in these three document subspaces can be
inter-connected with hyper-textual links – they can contain links to
other
documents – to documents stored in the same subspace, to documents
located in
another subspace, and to documents from outside of the system. Thus,
documents
within the system are organized using net-like structure. Moreover,
documents
located in these subspaces should contain links to elements of
a domain
model. Since each document subspace expects different way of
manipulating with
documents, three system’s modules are dedicated to them.
The Web
Content Management module offers means to manage the publishing
space. It enables to prepare documents in order to be published
(e.g. to
link them to elements of a domain model), to publish them, and to
access
them after they are published.
The
Discussion Forum module manages discussion space. The module enables
users to contribute to discussions they are interested in and/or to
read
contributions submitted by other users.
The Opinion
Polling Room module represents a tool for performing
opinion polling on different topics. Users can express their opinions
in the
form of polling – selecting those alternatives they prefer.
In order to
navigate among information stored in the system in an easy
and effective way, one more layer has been added to the system. This
layer is
focused on retrieving relevant information from the system in various
ways. Two
modules represent it, each enabling easy access to the stored
information in
a different way. The Citizens’ Information Helpdesk module is
dedicated to
search. It represents a search engine based on the indexing of
stored documents.
Its purpose is to find all those documents that match user’s
requirements
expressed in the form of a query.
The other
module performing information retrieval is the Reporter
module. This module is dedicated to providing information of two types.
The
first type represents information in an aggregated form. It enables to
define
and generate different reports concerning information stored in the
system. The
other type is focused on providing particular documents – but unlike
the CIH
module it is oriented on off-line mode of operation. It monitors
content of the
document space on behalf of the user and if information the user may be
interested in appears in the system, it sends an alert to him/her.
The upper
layer of the presented functional structure of the system is
represented by a user interface. It integrates functionality of all the
modules
accessible to a particular user into one coherent portal to the
system and
provides access to all functions of the system in a uniform way.
In order for
the system to be able to provide required functionality in
a real setting, several security issues must be solved. This is
the aim of
the Communication, Security, Authentication and Privacy module [5].
The system
enables to define, open, and use many communication channels
between citizens and a local authority. The purpose of these channels
can vary
from one-to-one communication (e.g. between a citizen and a
representative) to
many-to-many mode of operation (e.g. informing all citizens about
upcoming
events). They enable citizens to submit their ideas and proposals to
municipalities, ask anything about the municipality, obtain information
on
services of local government and events, communicate with
representatives and
departments of the institution, join public discussions on various
local and
non-local issues, etc.
Technical
achievements comprise a system designed to provide automatic
routing of messages from citizens to the appropriate person within the
public
administration; tools for easy access to public administration
information and
to competitive tendering; discussion forums involving citizens and
government
representatives; on-line opinion polling on defined issues of public
interest;
tools for identification, authentication and security built into the
system;
tools for navigation and browsing through a 'pool' of information,
documents,
and emails at territorial levels.
References
[1]
Abecker A., Bernardi A. Hinkelmann K. Kühn,
O. & Sintek M. (1998):
Toward a Technology for Organizational Memories, IEEE Intelligent
Systems, 13, May/June, p.40-48.
[2]
Baeza-Yates, R. & Ribeiro-Neto,
B. (1999) Modern
Information
Retrieval. Addison-Wesley Longman Publishing Company.
[3]
Borghoff U. M. & Pareschi R.
Eds. (1998) Information Technology for
Knowledge Management. Springer Verlag.
[4]
Chandrasekaran B., Josephson J.R.
& Benjamins V.R. (1999) What Are
Ontologies and
Why Do We Need Them. IEEE Intelligent Systems, 14, p. 20-26.
[5]
Dridi, F., Pernul, G. &
Unger, V: Security for the Electronic Government, Proc. of the 14th
Bled Electronic Commerce Conference, "e-Everything: e-Commerce,
e-Government, e-Household, e-Democracy", Bled, Slovenia, June 2001.
[6]
Gruber T.R. (1993) A Translation approach to Portable Ontology
Specifications. Knowledge Acquisition, 5, 2.
[7]
Paralic, M., Sabol, T. & Mach,
M. (2000) System Architecture for Support of Knowledge Management. Int.
Journal
of Advanced Computational Intelligence, Vol. 4, No. 4, Fuji
Technology
Press Ltd., Japan
[8]
Motta E. & Zdrahal Z.
(1998) A principled approach to the construction of a task-specific
library of
problem solving components. Proceedings of the 11th Banff
Knowledge
Acquisition for KBS Workshop, Canada.
[9]
Newell A. (1982) The
Knowledge Level. Artificial Intelligence, 18, p. 87-127.
[10]
Nonaka I. & Takeuchi H. (1995) The Knowledge Creating
Company: How Japanese Companies Create the Dynamics of Innovation.
Oxford Univ. Press.
[11]
Paralič, J. & Sabol, T. (2001) Implementation
of e-Government Using Knowledge-Based System. Proc. of the 12 th Int. Workshop on Database and Expert Systems
Applications, (Workshop on Electronic Government), Munich, 364-368.
[12]
Tiwana A. (2000) The Knowledge
Management Toolkit. Prentice Hall.
[13]
van Heijst G., Schreiber A.T.
& Wielinga, B.J. (1997) Using explicit
ontologies
in KBS development. Int. Journal of Human-Computer Studies, 46, p.
183-292.
Ontology-based
Information Retrieval
Authors: Ján Paralič, Ivan Koštiaľ
This paper was published in: Proc. of the 14th
International Conference on Information and Intelligent systems (IIS
2003), Varazdin, Croatia, p. 23-28
TRIALOGICAL
LEARNING IN
PRACTICE
Authors: František Babič, Peter
Bednár, Karol Furdík,
Ján Paralič, Marek
Paralič, Jozef
Wagner
Paper was
published
in Acta Electrotechnica et Informatica Vol. 8, No. 1 (2008),
p. 32–38
Design
and evaluation of a web system supporting various text mining
tasks for purposes of education and research
Authors: Karol FURDÍK,
Ján Paralič,
František Babič,
Peter Butka, Peter Bednár
This paper was published in: Acta
Electrotechnica et
Informatica. Vol. 10, No. 1
(2010), s. 51-58
Example
for exercises – information retrieval part
Let us assume
that we have the following small collection of five documents:
D1: You can
learn about knowledge in
Knowledge discovery and Knowledge management subjects.
D2:
Information retrieval is taught within
Knowledge management.
D3: Knowledge
discovery from various types of
data is the subject of Knowledge management.
D4: Knowledge
discovery, information
retrieval and knowledge management are main themes of the conference
Knowledge
and workshop WIKT.
D5:
Conference Knowledge joined with
conference Datakon last year.
The goals
are:
1.
Construct
inverted index
2.
Construct
Boolean model incidence matrix term – document
3.
Calculate
Vector model representations of given documents for various weighting
schemes
4.
Calculate
Vector model representations of given queries for various weighting
schemes
5.
Calculate
similarity of documents with given queries for various weighting scheme
combinations
1. Create
sequence of pairs: <modified token, document ID>,
eliminate stop-words